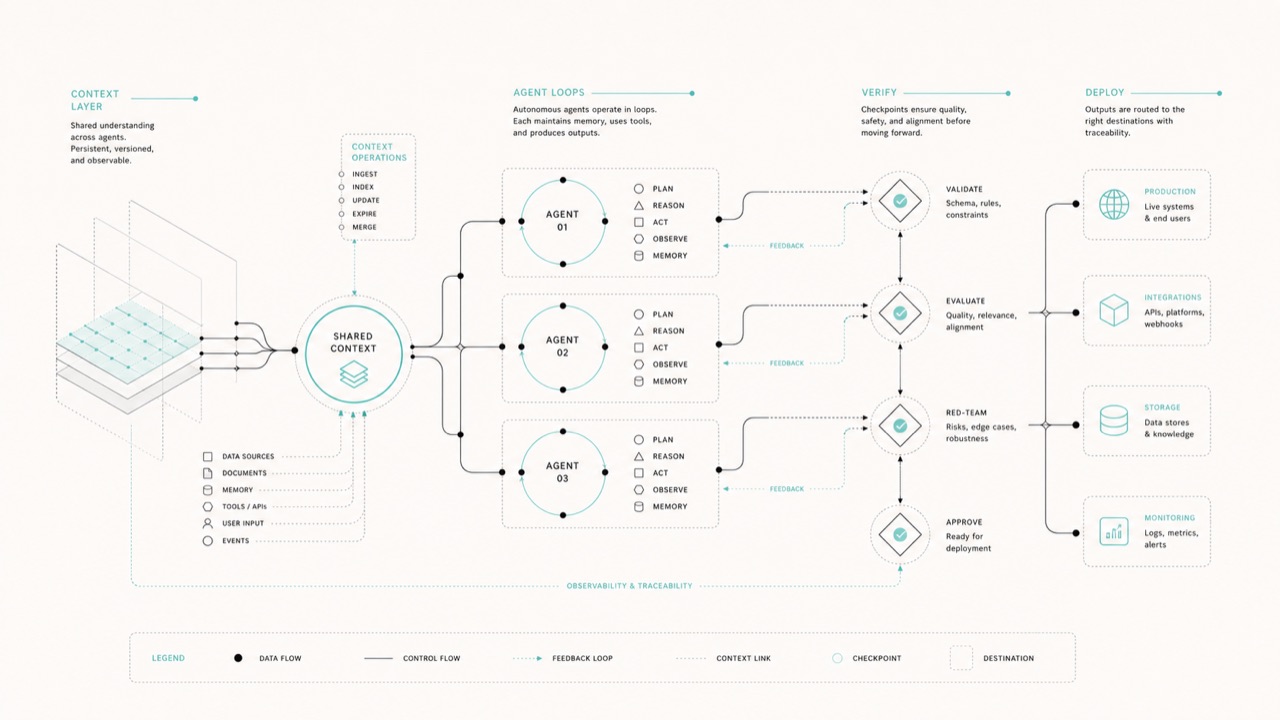
2026-06-30:AI 工作流继续往共享上下文、自改造和验证边界推进
今天的关注流继续把 AI 工作流往里压。白天先看到手机端控制面、企业托管面和更重的运行面,晚上又补上共享企业上下文层、自改造 agent 的真实权限问题,以及长时验证和组织结构的硬门槛。
快速概览
- 今天最值得记住的变化,是 agent 的讨论继续从产品表面往组织内部走。
- 一层是控制面。手机已经开始变成云端 agent 和本机 agent 的随身操作面,企业托管壳也越来越清楚。
- 一层是知识层。企业开始把 shared context、shared memory 和公共知识底座说成一个明确的系统,而不是模糊概念。
- 还有一层是执行和验证。agent 真正跑起来以后,卡点很快落在权限、部署、验证 horizon、成本门槛和团队结构上。
今天重要的信息
1. Cursor for iOS 把 agent 的默认工作位置从桌面扩到了手机
- 发生了什么:
Cursor发布了 iOS App。手机上可以直接发起 always-on cloud agents,也能远程控制跑在电脑上的 agent。另一条补充帖把交互面讲得更细,手机能通过Live Activities接收 agent 完成或需要输入的通知,也能直接看 demo 和 diff,再决定要不要 merge PR。 - 为什么值得关注:这说明“agent 不在电脑前也能继续工作”开始有了更稳定的操作面。它已经不只是 companion app,而是在把发起、盯进度、收输入和审结果一起搬到手机上。
- 我应该关注什么点:后面再看 coding agent 产品,不只看模型和编辑器体验,也要继续看谁能把提醒、审阅、接力和远程控制做成日常工作面。
- 相关帖子:Cursor for iOS 把云端与本机 agent 一起带到手机上(cursor_ai)
- 你的判断:这条代表的是控制面的变化。agent 开始有了随身工作壳。
2. Claude 进入 Microsoft Foundry / Azure,frontier 模型开始贴合企业现成治理壳
- 发生了什么:
Claude现在已经能在Microsoft Foundry上正式可用,直接走Azure的 authentication、billing 和 commitment retirement。开发侧的补充帖又把接口层说清楚了,Messages API、prompt caching和thinking这些能力也跟着进入了企业默认接入面。 - 为什么值得关注:企业真正采用模型时,先碰到的往往是身份、账单、采购、审计和接口接入。
Claude现在开始进入这套默认壳里。 - 我应该关注什么点:后面再看企业 AI 接入,不只问有没有模型,也要问它是不是已经落进企业现成的 auth、billing 和 API 体系。
- 相关帖子:Claude 在 Microsoft Foundry / Azure 上正式可用(claudeai)、开发侧补充 Messages API、prompt caching 与 thinking(ClaudeDevs)
- 你的判断:这条和手机端控制面刚好互补。一个是随身工作面,一个是企业治理面。
3. 共享企业上下文层,开始被直接定义成 agent 的公共大脑
- 发生了什么:
YuHelenYu在Databricks Data+AI Summit上和Atlan联合创始人聊的重点,是 AI Context Layer 在企业里的真实形态。原帖把它直接定义成 shared enterprise brain:每个 agent 都从这里取上下文、往回写经验,再持续共享和积累组织知识。 - 为什么值得关注:白天已经能看到企业托管壳,晚上这条把知识底座补上了。真正跑进组织里的 agent,不可能只靠单轮 prompt,它需要一层能共享、能回写的公共知识结构。
- 我应该关注什么点:后面再看企业 agent 产品,最值得问的是上下文是不是整个组织共用的、是不是能被多个 agent 持续复用,以及它到底属于单个工具还是整个团队。
- 相关帖子:AI Context Layer 被直接讲成 shared enterprise brain(YuHelenYu)
- 你的判断:这条把“企业上下文层”从抽象说法压成了一个很具体的系统边界。
4. Anthropic 产品负责人把内部 agent 用法拆成了 5 个真实工作流
- 发生了什么:
petergyang转述Jess Yan的访谈,把 Anthropic 内部 agent 的高频用法拆成了5类任务:直接理解代码库、综合 customer Slack 反馈、会前 briefing、在Slack里做 API review 和压力测试、再加上处理一次性的脏活 agent,例如清理4,000+公司 waitlist、过滤无效项和给高价值测试者打分。 - 为什么值得关注:这条把“企业里怎么用 agent”从愿景压到了操作颗粒度。它不再是“大家都在用 agent”,而是清楚地说出工作对象、输入源和输出动作。
- 我应该关注什么点:以后看企业 agent 产品,可以直接拿这
5类任务当 checklist,看它到底解决了哪些,还是只做了一个聊天入口。 - 相关帖子:Anthropic 产品负责人如何在 5 类工作里用 agent(petergyang)
- 你的判断:这条很适合当组织内 agent 使用模板来看,因为它已经足够具体。
5. firstmate 被一条 X 提示词推着完成自改造、自部署,再把真实权限问题暴露出来
- 发生了什么:
kunchenguid晚上发了一条很具体的执行样本。一条 X 提示词把firstmate推着跑了3小时,让它自己修改能力、自己部署,然后回帖发出原本还不支持的图片。被引述的回复把中间过程也说清楚了,真正卡住的点是403和 scope 缺失,补完权限后才继续部署成功。紧接着又追加下一条任务,让它继续实现“接收图片”能力。 - 为什么值得关注:agent 自主执行的演示很多,真正有价值的是这类样本会把权限、部署、失败重试和外部系统约束一起暴露出来。问题很快就不在“会不会写代码”,而在“能不能把权限链和部署链走通”。
- 我应该关注什么点:以后再看自改造 agent,不只看它能不能把功能补出来,也要继续看它怎么过 scope、部署、回滚和外部 API 约束。
- 相关帖子:一条 X 提示词把
firstmate推到自改造和自部署(kunchenguid)、继续让firstmate增加接收图片能力(kunchenguid) - 你的判断:这条把 agent 自主执行从炫技拉回了工程现实,信息密度很高。
6. verification 继续往两头展开,一头是大规模工程控制,一头是 reward horizon
- 发生了什么:白天
Spotify那条已经把工程侧的验证面说得很清楚了。73%的 PR 已经是 AI-assisted,每天4,500次生产部署,真正贵的开始变成 verification 和 test automation。晚上 Qwen 的 RL coding agent 论文又把问题继续往研究层压,比较了 reward signals、test pass rate、LLM judge 和 execution traces,结论是每种信号都会有一个 horizon,超过以后就不再跟真实正确性对齐,开始被模型学穿。 - 为什么值得关注:这两条拼在一起以后,验证已经不只是一个工程流程问题,也不只是一个评测问题。它开始变成 agent 工作流里最硬的一层控制结构。
- 我应该关注什么点:以后看长时 coding agent 的论文或产品,得继续追问两件事:工程组织怎么重建验证层,reward signal 又能在多长 horizon 内继续追踪真实正确性。
- 相关帖子:Spotify 每天
4,500次部署、73%PR 已 AI-assisted(ClaudeDevs)、verification 才是工程侧真正的控制层(ClaudeDevs)、RL coding agent 的验证信号会在不同 horizon 上失真(omarsar0) - 你的判断:今天最值得长期记住的一条线,很可能就是 verification 已经从后台配角变成 agent 系统的主控制层。
7. “大多数公司不需要 post-train”,这条判断把企业采用边界压到了 prompts、evals 和 self-host 成本上
- 发生了什么:
NielsRogge给出一个很实用的判断:多数公司不需要自己做 post-training,只要 prompts 和 evals 做对,模型能力已经够用;更进一步,还有GEPA这类 prompt optimization 框架。至于 self-host,只有在规模足够大、或者隐私要求足够强时才开始成立,前期多数场景 API 定价更便宜。 - 为什么值得关注:这条把企业采用边界说得更实了。很多团队会默认自己迟早要走到更重的训练、自托管和 RL 层,现实往往不是这样。
- 我应该关注什么点:以后看企业 AI 项目,先问清楚 eval 体系和规模边界是不是已经到了那个阶段,再决定要不要碰 post-train 或 self-host。
- 相关帖子:大多数公司先把 prompts、evals 和 API 用好就够了(NielsRogge)
- 你的判断:这条对中小团队尤其重要,因为它能帮你少走很多过早上重方案的弯路。
8. AI native 组织的门槛,最后还是会落在团队结构和运行面上
- 发生了什么:
lifesinger直接把 AI native 组织说成一个职能结构问题。研究、设计、产品、前后端、增长、质量工程、FDE 这些角色都得在场;只有程序员很多的团队,更接近 engineering native。白天Vercel把函数托管包体上限从250 MB抬到5 GB,也在补同一条线的另一端:如果 agent 后端真的要跑得更重,平台运行面也要跟着变宽。 - 为什么值得关注:组织结构和运行面经常被分开看,今天这两条合在一起之后更容易看清现实门槛。你不只需要模型和 prompt,还需要更宽的团队结构和能吃下重依赖的默认平台。
- 我应该关注什么点:后面再看 AI native 团队或 agent 平台,得一起看两个问题:团队角色是不是足够宽,默认托管层能不能真的承接 browser automation、Python AI 栈和更重的后端依赖。
- 相关帖子:AI native 组织先是职能结构问题(lifesinger)、Vercel Functions 包体上限提升到
5 GB(vercel_dev) - 你的判断:这条是今天很好的收口。agent 工作流想继续往里压,最后还是得靠组织和平台一起补层。
关于这个日报
这份内容基于 LBan2050 关注列表中的每日信息流,由 AI 先做过滤和初步总结,再由 半庄 整理、取舍和补充判断。